Claude Vision là gì ?
Claude 3 mang đến khả năng thị giác (Vision mode) mới mẻ, cho phép Claude hiểu và phân tích hình ảnh. Đây là bước đột phá mở ra những tương tác đa phương thức thú vị. Giờ đây, bạn có thể cung cấp cho Claude cả đầu vào dạng văn bản và hình ảnh để làm phong phú cuộc trò chuyện và kích hoạt các chức năng mạnh mẽ.
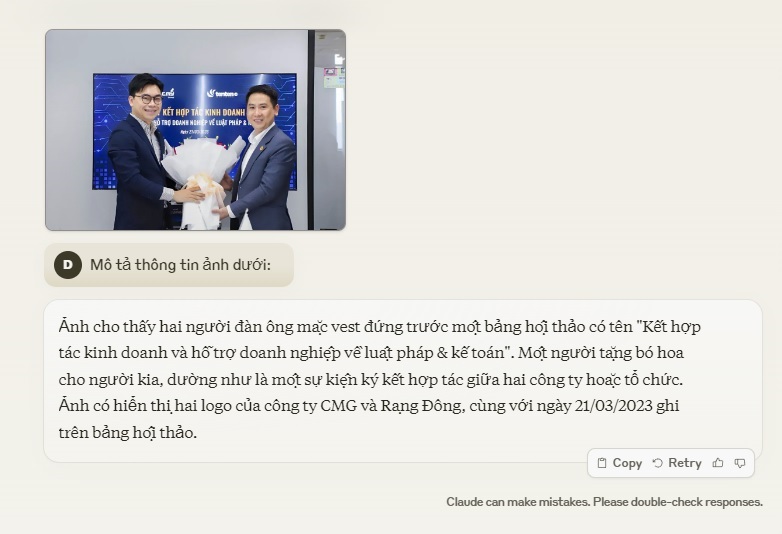
Điều tuyệt vời là bạn không cần phiên bản Claude 3 đặc biệt nào để sử dụng tính năng này. Tất cả các model Claude 3 đều có khả năng hiểu và phân tích hình ảnh.
Để tìm hiểu thêm về cách sử dụng hình ảnh trong Claude 3, bạn có thể tham khảo hướng dẫn chi tiết, bao gồm các phương pháp hay nhất, ví dụ về code và những lưu ý về hạn chế.
Bài viết liên quan: Claude 3 Haiku: “Chất lượng hơn” GPT 3.5 và Gemini 1.0 Pro
Bắt đầu sử dụng
Claude 3 cung cấp khả năng hiểu và phân tích hình ảnh. Chế độ Vision (Tầm nhìn) cho phép bạn tận dụng sức mạnh này theo ba cách chính:
- Trực tiếp trên claude.ai: Bạn có thể tải ảnh lên cửa sổ chat giống như tải lên một file thông thường, hoặc kéo thả ảnh trực tiếp vào cửa sổ.
- Thông qua Console Workbench: Chọn một model hỗ trợ hình ảnh (chỉ các model Claude 3). Khi đó, nút thêm ảnh sẽ xuất hiện ở phía trên bên phải của mỗi khối tin nhắn Người dùng (User).
- Yêu cầu API: Tham khảo hướng dẫn chi tiết (không có trong đoạn trích dẫn này).
Tuy nhiên, ở bài viết này sẽ hướng dẫn chủ yếu về cách sử dụng Claude Vision thông qua API.
Hướng dẫn sử dụng thông qua API
Hướng dẫn này không đề cập đến việc sử dụng SDK Python của Anthropic, mà chỉ cung cấp một ví dụ đơn giản về cách Claude 3 có thể nhận và xử lý ảnh được mã hóa base64 trong yêu cầu API của Messages.
Lưu ý: Phần code Python được trích dẫn chỉ nhằm mục đích minh họa và không cần thiết để sử dụng Vision mode của Claude 3.
import anthropic
import base64
import httpx
client = anthropic.Anthropic()
image1_url = "https://tenten.vn/tin-tuc/wp-content/uploads/2023/03/GMO-Viet-My-Chuyen-doi-so-Khoi-nghiep-1-1024x683.jpg"
image1_media_type = "image/jpeg"
image1_data = base64.b64encode(httpx.get(image1_url).content).decode("utf-8")
Vision mode cho phép bạn tận dụng hình ảnh để hỗ trợ Claude 3 trong quá trình xử lý thông tin. Bạn có thể kết hợp hình ảnh và văn bản để Claude 3 hiểu được yêu cầu của bạn tốt hơn.
message = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": image1_media_type,
"data": image1_data,
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)
Bạn có thể cung cấp hình ảnh cho Claude 3 dưới dạng các định dạng phổ biến như JPEG, PNG, GIF và WebP.
Kích thước ảnh
- Để có hiệu suất tốt nhất, nên resize ảnh trước khi tải lên nếu kích thước vượt quá giới hạn. Giới hạn kích thước được tính theo cả pixel và số token.
- Ảnh có chiều dài cạnh lớn nhất vượt quá 1568 pixel hoặc tổng số token vượt quá 1600 sẽ tự động được resize theo tỷ lệ khung hình gốc cho đến khi nằm trong giới hạn.
- Việc resize ảnh sẽ làm tăng thời gian phản hồi (time-to-first-token) nhưng không cải thiện hiệu quả phân tích.
- Ảnh quá nhỏ (bất kỳ cạnh nào nhỏ hơn 200 pixel) cũng có thể ảnh hưởng đến độ chính xác.
Khuyến nghị:
- Để cải thiện thời gian phản hồi, hãy resize ảnh xuống dưới 1.15 megapixel và giữ cả hai chiều nhỏ hơn 1568 pixel.
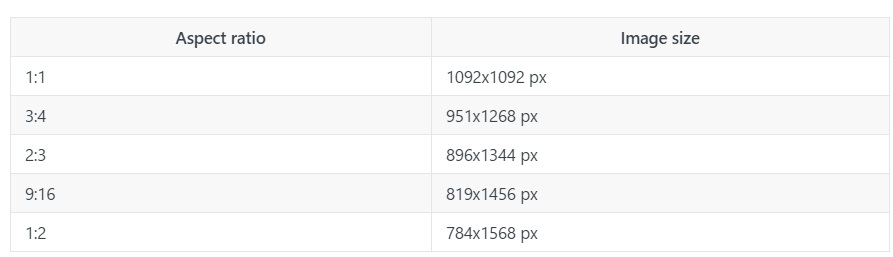
Bảng kích thước ảnh tối đa theo tỷ lệ khung hình:
Bảng dưới đây liệt kê các kích thước ảnh tối đa được chấp nhận bởi API của Claude 3 theo các tỷ lệ khung hình thông dụng. Những ảnh này sẽ không bị resize và ước tính tương đương với khoảng 1600 token và chi phí khoảng $4.80 trên 1000 ảnh (giả sử sử dụng Claude 3 Sonnet).
Hiệu suất tối đa nhất
Để tạo ra chất lượng kết quả đầu ra tốt nhất, xin lưu ý với 4 quy tắc sau đây:
Chất lượng ảnh: Ảnh cần rõ ràng, không bị mờ hoặc vỡ nét. Claude có thể gặp khó khăn khi xử lý ảnh không rõ ràng hoặc chất lượng thấp.
Vị trí ảnh: Giống như việc đặt câu hỏi với văn bản, Claude hoạt động tốt nhất khi ảnh được đặt trước văn bản. Ảnh đặt sau văn bản hoặc xen kẽ với văn bản vẫn hoạt động tốt, nhưng nếu ngữ cảnh cho phép, bạn nên đặt ảnh trước rồi đến văn bản.
Văn bản trong ảnh: Nếu ảnh chứa văn bản quan trọng, hãy đảm bảo văn bản đó dễ đọc và không quá nhỏ. Tuy nhiên, tránh cắt xén phần tử hình ảnh quan trọng chỉ để phóng to văn bản.
Nhiều ảnh: Bạn có thể bao gồm nhiều ảnh trong một yêu cầu (tối đa 5 ảnh trên claude.ai và 20 ảnh cho yêu cầu API). Claude sẽ phân tích tất cả ảnh được cung cấp để xây dựng câu trả lời. Tính năng này hữu ích để so sánh hoặc đối chiếu các hình ảnh.
Mẹo sử dụng PROMPT
Bạn có thể cung cấp cho Claude 3 cả văn bản và hình ảnh để làm phong phú cuộc trò chuyện và thực hiện các tác vụ mới mạnh mẽ.
Ví dụ: bạn có thể hiển thị một bức ảnh và yêu cầu Claude 3 mô tả nội dung, phân tích cảm xúc trong ảnh, hoặc thậm chí sáng tạo văn bản dựa trên hình ảnh đó.
Để tận dụng tối đa Vision mode, hãy lưu ý mẹo nhỏ: cung cấp hình ảnh trước khi đặt câu hỏi về chúng hoặc hướng dẫn thực hiện tác vụ liên quan. Nếu có nhiều ảnh, hãy giới thiệu từng ảnh với chú thích “Ảnh 1:”, “Ảnh 2:”, v.v.
Claude 3 sẽ hỗ trợ bạn tương tự như khi xử lý văn bản, giúp bạn khai thác thông tin từ hình ảnh hiệu quả hơn.
Gọi một hình ảnh
| Role | Content |
|---|---|
| User | [Image] Mô tả nội dung |
message = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": image1_media_type,
"data": image1_data,
},
},
{
"type": "text",
"text": "Mô tả nội dung ảnh."
}
],
}
],
)
Gọi nhiều hình ảnh
| Role | Content |
|---|---|
| User | Image 1: [Image 1] Image 2: [Image 2] Sự khác biết giữa 2 bức ảnh? |
Lưu ý: Khi sử dụng gọi nhiều hình ảnh thì thường để so sánh hơn là miêu tả nội dung.
message = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Image 1:"
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": image1_media_type,
"data": image1_data,
},
},
{
"type": "text",
"text": "Image 2:"
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": image2_media_type,
"data": image2_data,
},
},
{
"type": "text",
"text": "How are these images different?"
}
],
}
],
)
Gọi nhiều hình ảnh với vai trò riêng
| Content | |
|---|---|
| System | Bạn là chuyên ra phân tích hình ảnh. |
| User | Image 1: [Image 1] Image 2: [Image 2] Tìm ra sự khác biệt. |
message = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
system="Bạn là chuyên ra phân tích hình ảnh..",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Image 1:"
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": image1_media_type,
"data": image1_data,
},
},
{
"type": "text",
"text": "Image 2:"
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": image2_media_type,
"data": image2_data,
},
},
{
"type": "text",
"text": "Tìm ra sự khác biệt.?"
}
],
}
],
)
Giá cả
- Mỗi hình ảnh được bao gồm trong yêu cầu gửi đến Claude 3 sẽ tính vào tổng số token sử dụng.
- Để ước tính chi phí gần đúng, bạn cần nhân số token hình ảnh dự kiến với giá mỗi token của model đang sử dụng. Bạn có thể tìm thấy chi tiết về giá model trên trang giá của Anthropic.
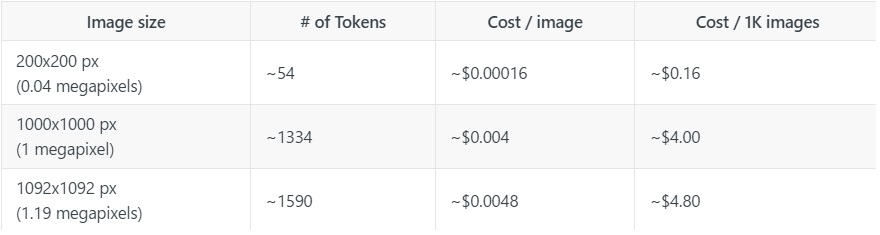
Ước tính số token hình ảnh:
- Giả sử không cần thay đổi kích thước ảnh, bạn có thể ước tính số token được sử dụng bằng thuật toán đơn giản:
tokens = (chiều rộng px * chiều cao px) / 750Ví dụ:
Bảng ví dụ (không hiển thị trong văn bản này) cho thấy chi phí ước tính của việc sử dụng hình ảnh với các kích thước khác nhau trong giới hạn kích thước của API, giả sử sử dụng Claude 3 Sonnet với giá 3 USD trên một triệu token đầu vào.
Giới hạn
Claude 3 sở hữu khả năng hiểu hình ảnh tiên tiến, nhưng cũng có một số hạn chế cần lưu ý:
- Nhận dạng người: Claude không thể được sử dụng để nhận dạng người trong ảnh và sẽ từ chối thực hiện tác vụ này.
- Độ chính xác: Claude có thể đưa ra kết quả ảo hoặc sai sót khi phân tích hình ảnh chất lượng thấp, bị xoay hoặc ảnh rất nhỏ (dưới 200 pixel).
- Lý luận không gian: Khả năng lý luận không gian của Claude còn hạn chế. Nó có thể gặp khó khăn với các tác vụ yêu cầu định vị chính xác hoặc bố cục, chẳng hạn như đọc mặt đồng hồ analog hoặc mô tả vị trí chính xác của các quân cờ.
- Đếm vật thể: Claude có thể cung cấp số lượng gần đúng các vật thể trong ảnh nhưng không phải lúc nào cũng chính xác, đặc biệt với nhiều vật thể nhỏ.
- Hình ảnh do AI tạo ra: Claude không phân biệt được hình ảnh do AI tạo ra và có thể trả kết quả không chính xác khi được hỏi. Không nên tin tưởng Claude để phát hiện ảnh giả hoặc tổng hợp.
- Nội dung không phù hợp: Claude sẽ không xử lý hình ảnh không phù hợp hoặc nhạy cảm, vi phạm Chính sách sử dụng chấp nhận của chúng tôi.
- Ứng dụng chăm sóc sức khỏe: Mặc dù Claude có thể phân tích các hình ảnh y tế tổng quát, nhưng nó không được thiết kế để giải thích các bản quét chẩn đoán phức tạp như CT hoặc MRI. Kết quả của Claude không nên được coi là thay thế cho lời khuyên hoặc chẩn đoán y tế chuyên nghiệp.
Bài viết liên quan: Tìm hiểu về Claude 3 – Model AI thế hệ mới của Anthropic
Chúc các bạn thao tác thành công !
Nguồn: anthropic.com