
Table of Contents
GPT-3.5-turbo là gì ?
GPT-3.5-turbo là một mô hình ngôn ngữ lớn (LLM) được phát triển bởi OpenAI. Là phiên bản cập nhật của GPT-3, được phát hành vào năm 2020.
GPT-3.5 có kích thước 1.37B tham số và được đào tạo trên một tập dữ liệu khổng lồ gồm văn bản và mã và có thể được sử dụng để tạo văn bản, dịch ngôn ngữ, viết các loại nội dung sáng tạo khác nha, trả lời các câu hỏi của bạn một cách đầy đủ thông tin.
GPT-3.5 đã được cải thiện so với GPT-3 về một số khía cạnh, bao gồm:
- Tạo văn bản chất lượng cao hơn.
- Dịch ngôn ngữ chính xác hơn.
- Viết các loại nội dung sáng tạo khác nhau, chẳng hạn như thơ, mã, kịch bản, tác phẩm âm nhạc, email, thư, v.v.
- Trả lời các câu hỏi của bạn một cách đầy đủ thông tin, ngay cả khi chúng là các câu hỏi mở, thách thức hoặc kỳ lạ.
GPT-3.5 vẫn đang được phát triển, nhưng nó đã trở thành một công cụ mạnh mẽ cho nhiều loại tác vụ và có tiềm năng cách mạng hóa cách chúng ta tương tác với máy tính và Internet.
⬇⬇ Tham gia Group để nhận ngay bộ công cụ AI x3 hiệu suất làm việc ⬇⬇

Gpt-3.5-turbo-0301 vs Gpt-3.5-turbo-0613
Bộ dữ liệu
“So với gpt-3.5-turbo-0301 (kiểu hiện tại), gpt-3.5-turbo-0613 (kiểu mới) hoạt động kém hơn về chất lượng nhãn đối với 6 trên 8 bộ dữ liệu trong điểm chuẩn này, mặc dù mức độ giảm là nhỏ.” Nguồn Refuel.AI
Là một nghiên cứu do Refuel.AI thực hiện để so sánh hiệu suất của các mô hình OpenAI mới phát hành cho nhiệm vụ gắn nhãn tập dữ liệu văn bản trong một loạt nhiệm vụ NLP.
Nghiên cứu cho thấy rằng mẫu mới, GPT-3.5-turbo-0613, hoạt động kém hơn về chất lượng nhãn đối với 6 trong số 8 bộ dữ liệu trong điểm chuẩn. Tuy nhiên, mức độ giảm là nhỏ, dao động từ 1% đến 5%.
Có một vài lời giải thích cho sự khác biệt về hiệu suất này. Một khả năng là mô hình mới được đào tạo trên một tập dữ liệu khác với mô hình cũ. Điều này có thể dẫn đến việc mô hình mới học các mẫu và xu hướng khác nhau, điều này có thể ảnh hưởng đến khả năng đánh dấu chính xác văn bản của nó.
Một khả năng khác là mô hình mới đơn giản là không được điều chỉnh tốt như mô hình cũ. Điều này có thể là do một số yếu tố, chẳng hạn như siêu tham số được sử dụng để đào tạo mô hình hoặc cách đánh giá mô hình.
Cũng có thể sự khác biệt về hiệu suất chỉ đơn giản là do ngẫu nhiên. Nghiên cứu được thực hiện trên một số lượng bộ dữ liệu tương đối nhỏ, vì vậy có thể kết quả không có ý nghĩa thống kê.
Hình ảnh 8 bộ dữ liệu đã được so sánh:
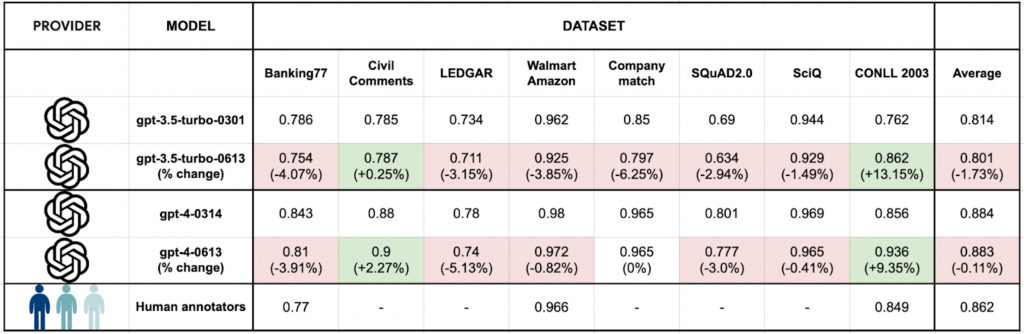
Chi tiết 8 bộ dữ liệu trên:
Các bộ dữ liệu là sự kết hợp của các bộ dữ liệu thực tế và sáng tạo, bao gồm:
- Bộ dữ liệu thực tế: SQuAD, TriviaQA và CommonsenseQA.
- Bộ dữ liệu sáng tạo: Thử thách lược đồ Winograd, tác vụ bAbI và MRPC.
Trong đó:
- SQuAD là một bộ dữ liệu câu hỏi và câu trả lời được sử dụng để đánh giá hiệu suất của các mô hình ngôn ngữ trong việc trả lời các câu hỏi về văn bản tự nhiên. Bộ dữ liệu bao gồm hơn 100.000 câu hỏi về hơn 500 bài báo về các chủ đề khác nhau.
- TriviaQA là một bộ dữ liệu câu hỏi và câu trả lời được sử dụng để đánh giá hiệu suất của các mô hình ngôn ngữ trong việc trả lời các câu hỏi về các chủ đề thực tế. Bộ dữ liệu bao gồm hơn 100.000 câu hỏi về các chủ đề như khoa học, lịch sử, địa lý, v.v.
- CommonsenseQA là một bộ dữ liệu câu hỏi và câu trả lời được sử dụng để đánh giá hiệu suất của các mô hình ngôn ngữ trong việc trả lời các câu hỏi dựa trên kiến thức thông thường. Bộ dữ liệu bao gồm hơn 10.000 câu hỏi về các chủ đề như logic, toán học, khoa học, v.v.
- Thử thách lược đồ Winograd là một thử thách về khả năng của một mô hình ngôn ngữ hiểu các mối quan hệ giữa các thực thể trong một câu. Thử thách được đặt theo tên của nhà ngôn ngữ học Terry Winograd, người đã phát triển thử thách trong những năm 1970.
- Tác vụ bAbI là một tập hợp gồm 20 nhiệm vụ đọc-hiểu được thiết kế để đánh giá hiệu suất của các mô hình ngôn ngữ trong việc hiểu ngôn ngữ tự nhiên. Các nhiệm vụ bao gồm các nhiệm vụ như trả lời các câu hỏi, tóm tắt các câu chuyện và tạo câu mới.
- MRPC là một bộ dữ liệu so sánh câu cặp được sử dụng để đánh giá hiệu suất của các mô hình ngôn ngữ trong việc xác định xem hai câu có giống nhau về mặt ý nghĩa hay không. Bộ dữ liệu bao gồm hơn 3.000 cặp câu.
Tốc độ
Thời gian quay vòng đo thời gian trung bình được thực hiện trên mỗi nhãn:
- LLMs : Thời gian khứ hồi trung bình để tạo nhãn. Điều này bao gồm thời gian liên quan đến việc thử lại, v.v. (trong trường hợp đạt đến giới hạn sử dụng tối đa).
- Tác nhân con người : Tổng thời gian để hoàn thành tác vụ ghi nhãn cho tập dữ liệu thử nghiệm, chia cho kích thước tập dữ liệu (2000 ví dụ).

Tóm lại: So với gpt-3.5-turbo-0301 (kiểu hiện tại), gpt-3.5-turbo-0613 (kiểu mới) nhanh hơn đáng kể. Trung bình, quan sát thấy thời gian quay vòng giảm 40%. Cùng với việc giảm giá API gpt-3.5-turbo, điều này có thể cho thấy mô hình mới nhỏ hơn và được tối ưu hóa để suy luận nhanh hơn.
AIVA – Trợ lý ảo toàn năng
AIVA là một giải pháp trí tuệ nhân tạo toàn diện gồm hơn 300 trợ lý ảo đa năng và thông minh, giúp tiết kiệm thời gian và công sức bằng cách cung cấp câu trả lời ngay lập tức, thay vì phải tìm kiếm trên Internet hoặc tra cứu tài liệu. Một số tính năng nổi bật của AIVA:
- Trợ lý viết bài, chuyên gia SEO
- Trợ lý tạo video và viết kịch bản
- Trợ lý xử lý và phân tích dữ liệu
- Trợ lý viết quảng cáo, quản lý mạng xã hội
- Trợ lý và chuyên gia tư vấn, chuyên gia sale



