
GPT-5 ra mắt khi nào ?
Theo dự đoán, GPT-5 sẽ được phát hành vào tháng 11, có thể trùng với kỷ niệm 2 năm ra mắt bùng nổ của ChatGPT. Cùng thời điểm đó, chúng ta cũng sẽ đón chào các mô hình đột phá khác như Gemini 2 Ultra, LLaMA-3, Claude-3, Mistral-2.
Sự cạnh tranh trong lĩnh vực này ngày càng khốc liệt, tiêu biểu là cuộc đua giữa Gemini của Google và GPT-4 turbo.

Rất có khả năng GPT-5 sẽ được phát hành theo từng giai đoạn, đây là những điểm kiểm tra trung gian trong quá trình huấn luyện mô hình. Tổng thời gian đào tạo có thể kéo dài 3 tháng, cộng thêm 6 tháng để kiểm tra an ninh.
Để hiểu rõ hơn về GPT-5, hãy cùng điểm qua các thông số kỹ thuật của GPT-4:

Dựa vào hình ảnh, ta sẽ thấy được:
Kích thước dữ liệu huấn luyện: Được so sánh với một dãy kệ thư viện dài 650 km, trong đó mỗi kệ đại diện cho 100.000 token và tổng cộng có 13 nghìn tỷ token.
Yêu cầu tính toán: Kích thước tính toán cần thiết để đào tạo, ước tính là 2,15 triệu tỷ (10 ^ 18) phép toán FLOP, được minh họa mất 7 triệu năm trên một máy tính xách tay cỡ trung bình với hiệu suất 100 GFLOP/giây.
Kích thước mô hình: Với 1,8 nghìn tỷ tham số, được so sánh với 30.000 bảng tính Excel có kích thước bằng một sân bóng đá cộng lại.
Bộ dữ liệu: GPT-4 được huấn luyện trên khoảng 13 nghìn tỷ token, bao gồm cả dữ liệu dạng văn bản và mã nguồn, với một số dữ liệu tinh chỉnh từ ScaleAI và nội bộ.
Trộn Bộ dữ liệu: Dữ liệu huấn luyện bao gồm CommonCrawl & RefinedWeb, tổng cộng 13 nghìn tỷ token. Đồn đoán cho rằng có các nguồn bổ sung như Twitter, Reddit, YouTube và một bộ sưu tập sách giáo khoa lớn.
Chi phí Huấn luyện: Chi phí huấn luyện cho GPT-4 khoảng 63 triệu USD, tính đến sức mạnh tính toán cần thiết và thời gian huấn luyện.
Chi phí Suy luận: GPT-4 có chi phí gấp 3 lần so với Davinci 175B tham số, do cần các cụm lớn hơn và tỷ lệ sử dụng thấp hơn.
Kiến trúc Suy luận: Suy luận chạy trên một cụm gồm 128 GPU, sử dụng song song tensor 8 chiều và song song pipeline 16 chiều.
Đa phương thức Thị giác: GPT-4 bao gồm một bộ mã hóa thị giác cho các tác nhân tự chủ để đọc các trang web và phiên mã hình ảnh và video. Điều này bổ sung thêm các tham số ở trên và được tinh chỉnh với khoảng 2 nghìn tỷ token khác.
GPT-5: Giờ đây, GPT-5 có thể có số tham số gấp 10 lần so với GPT-4 và điều này QUÁ KHỦNG! Điều này có nghĩa là kích thước nhúng lớn hơn, nhiều lớp hơn và gấp đôi số chuyên gia.
Tìm hiểu về GPT-5

Thông tin chính được truyền tải là GPT-4 được cho là có tổng cộng khoảng 1,831 nghìn tỷ tham số.
Kiến trúc được mô tả là mô hình Mixture of Experts (MoE), với 16 thành phần chuyên gia, mỗi thành phần chứa 111 tỷ tham số. Kết hợp lại, 16 chuyên gia này chiếm 1,776 nghìn tỷ tham số, được gọi là “tham số chuyên gia”.
Ngoài ra, còn có một thành phần chú ý được chia sẻ với 55 tỷ tham số.
Hình ảnh trực quan hóa 16 thành phần chuyên gia dưới dạng các biểu tượng giống như bộ não, mỗi thành phần chứa 111 tỷ tham số. Các chuyên gia này được kết nối với một ngăn xếp trung tâm gồm 120 lớp, có thể đại diện cho độ sâu hoặc số lớp của mô hình.
Thành phần chú ý được chia sẻ với 55 tỷ tham số được mô tả như một ngăn xếp màu xanh lớn ở phía dưới, tương tác với các thành phần chuyên gia.
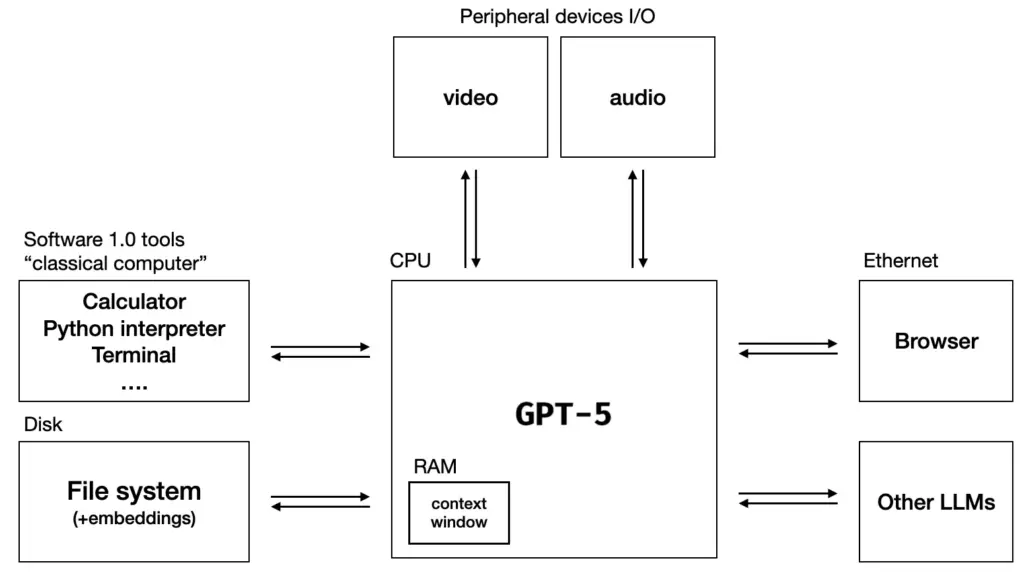
GPT-5 được "ví" như 1 hệ điều hành
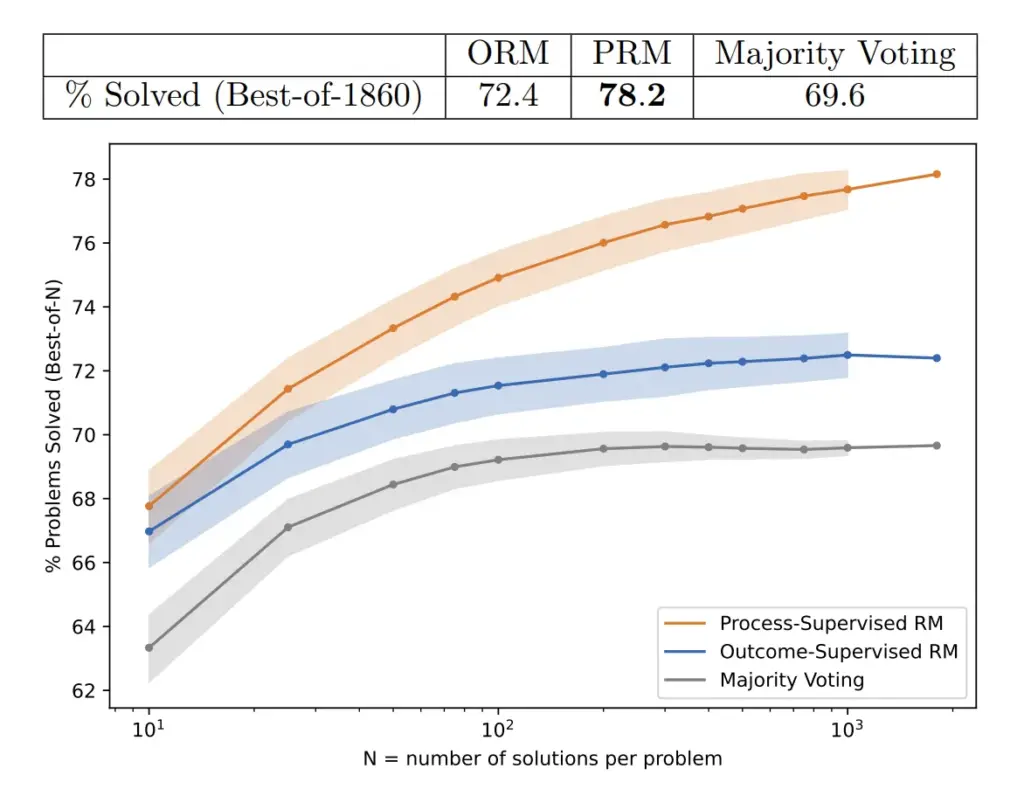
So sánh giữa các mô hình được giám sát kết quả và mô hình được giám sát quá trình, được đánh giá thông qua khả năng của chúng trong việc tìm kiếm qua nhiều giải pháp kiểm tra.
Việc lấy mẫu của mô hình hàng nghìn lần và chọn câu trả lời có các bước lý luận được đánh giá cao nhất đã làm tăng gấp đôi hiệu suất trong toán học và không, điều này không chỉ áp dụng cho toán học mà còn mang lại kết quả ấn tượng trong các lĩnh vực STEM.
GPT-5 cũng sẽ được huấn luyện trên một lượng dữ liệu lớn hơn nhiều, cả về Khối lượng, Chất lượng và Đa dạng.
Điều này bao gồm lượng dữ liệu Văn bản, Hình ảnh, Âm thanh và Video lớn. Cũng như Dữ liệu Đa ngôn ngữ và Lý luận.
Điều này có nghĩa là Đa dạng hình ảnh sẽ được cải thiện nhiều hơn trong năm nay trong khi Lý luận LLM bắt đầu phát triển.
Điều này sẽ khiến cho GPT-5 trở nên linh hoạt hơn, giống như việc sử dụng một LLM như một Hệ điều hành.
Năm 2024 sẽ là phiên bản rõ ràng và có thể áp dụng thương mại hơn của các mô hình hiện đang tồn tại và mọi người sẽ bất ngờ khi nhìn thấy mức độ tốt của những mô hình này đã trở nên.
Không ai thực sự biết được các mô hình mới sẽ như thế nào. Chủ đề lớn nhất trong lịch sử trí tuệ Nhân tạo là nó luôn đầy bất ngờ.
Mỗi khi bạn nghĩ bạn biết điều gì đó, bạn tăng cường nó lên 10 lần và cuối cùng bạn nhận ra bạn không biết gì cả. Chúng ta như một loài người đang thực sự khám phá điều này cùng nhau.
Tuy nhiên, toàn bộ tiến triển tổng hợp trong LLM và Trí tuệ Nhân tạo là một bước tiến về AGI.
source: medium.com



