- VIE
- VIE
- ENG
Trong bối cảnh yêu cầu truy xuất dữ liệu trên Internet ngày càng tăng cao thì việc sử dụng các công cụ hỗ trợ luôn là điều cần thiết. Trong đó, không thể không nhắc tới Web scraping – trợ thủ đắc lực giúp người dùng thu thập dữ liệu nhanh chóng. Tuy nhiên, hiện nay vẫn còn số ít người biết đến ứng dụng này. Phần lớn vì chúng chưa được phổ biến rộng rãi đến mọi người dùng ở thời điểm này. Nếu bạn đang có những thắc mắc liên quan tới ứng dụng trên thì đừng vội bỏ qua mà hãy tìm hiểu ngay bài viết này nhé!
Contents
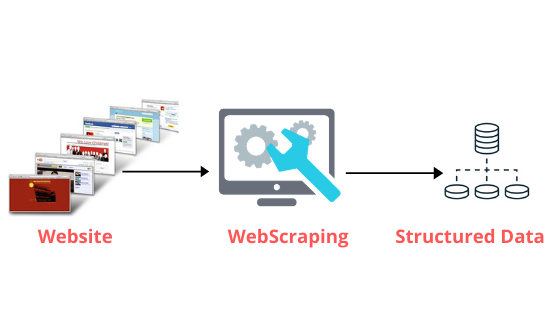
Hầu hết các diễn đàn hiện nay đều chưa có những thông tin chuẩn xác, đầy đủ xoay quanh thuật ngữ này. Vậy nên vẫn còn nhiều người chưa hiểu rõ Web Scraping là gì. Nói một cách tổng quát thì đây là ứng dụng thu thập dữ liệu từ các website. Chúng có nhiệm vụ trích xuất dữ liệu trực tiếp từ World Wide Web thông qua giao thức HTTP hoặc trình duyệt web.

Web Scraping là gì?
Trên thực tế, người dùng phần mềm hoàn toàn có thể quét web thủ công. Nhưng với những người có nghiệp vụ chuyên nghiệp thì thuật ngữ này mô tả cho quá trình tự động. Tất cả được tiến hành thông qua việc sử dụng bot hoặc trình thu thập thông tin web. Nhờ vậy mà bạn có thể thu thập và sao chép dữ liệu từ web nhằm phục vụ việc truy xuất hoặc phân tích.
Một điểm mà bạn cần phân biệt rõ ràng là hoạt động của web scraping khác hoàn toàn với web scraper. Bởi web scraper cũng hoạt động thông qua việc quét mã HTML của website, khá giống với scraping. Tuy nhiên, về bản chất thì web crawling trừu tượng hơn và thu thập tất cả thông tin từ website. Trong khi đó, scraping lại nhắm đến những tập dữ liệu cụ thể.
Chắc hẳn thuật ngữ “dữ liệu lớn” đã rất quen thuộc trong thời đại khoa học công nghệ 4.0 phải không nào? Đây cũng chính là điểm mấu chốt cần áp dụng web scraping để lấy được dữ liệu lớn với những thuật toán phức tạp.
Trong bối cảnh hiện nay, mọi doanh nghiệp đều phải bảo vệ cơ sở dữ liệu của mình, các cá nhân đều cố gắng bảo vệ quyền riêng tư. Thế nhưng, hầu hết tại các tập đoàn lớn thì việc có sẵn nguồn dữ liệu khổng lồ là rất ít. Và để có được dữ liệu, người ta chỉ có 3 cách – và chỉ có 1 cách tối ưu nhất:
Ứng dụng của Web Scraping
Theo thống kê của Linkedin tại Mỹ thì công nghệ này được sử dụng lên tới 54 lĩnh vực khác nhau. Trong đấy, có 10 lĩnh vực phổ biến nhất phải nói tới gồm:
Theo ứng dụng thực tế, nhiều báo cáo chỉ ra rằng các bot scraper độc hại ngày càng tăng cao. Chúng có khả năng phá vỡ lớp bảo mật của công nghệ này. Và khiến các biện pháp bảo mật sẵn có bị vô hiệu hoá. Hiện tại, để hạn chế tình trạng bot scraper “xâm chiếm”, nhiều công ty đã có những biện pháp mới. Trong đó phải kể tới công ty Imperva đã nhanh chóng sử dụng phương pháp phân tích lưu lượng truy cập chi tiết. Cách này có thể đảm bảo lưu lượng truy cập đến website, bao gồm cả người và bot.
Quy trình này sẽ bao gồm những nội dung sau:
Hy vọng qua những thông tin vừa rồi, bạn đã hiểu kỹ hơn về web scraping. Để cập nhật thêm những bài viết bổ ích xoay quanh website, hosting hay tền miền,…đừng quên truy cập ngay Tenten.vn nhé!
| Web scraping Python | Scraping là gì |
| Web Scraping Python là gì | Screen Scraping là gì |
| Data scraping là gì | Scraping |
| Web scraping extension | Scraping a living |
[HƯỚNG DẪN] 3 cách tạo tệp robots txt đơn giản cho WordPress



