- VIE
- VIE
- ENG
Machine Learning (học máy) là một khái niệm trong đó một chương trình máy tính có thể học và tự xử lý các dữ liệu mới mà không cần đến sự can thiệp của con người. Học máy đã và đang mang lại những tác động to lớn đối với đời sống con người. Hãy cùng Tenten.vn tìm hiểu về machine learning là gì và các ứng dụng của học máy.

Contents
Machine learning là gì? Machine learning là một lĩnh vực thuộc trí tuệ nhân tạo (AI), xoay quanh các thuật toán nhằm xác định mẫu hình và mối liên hệ trong dữ liệu. “Máy” ở đây đồng nghĩa với chương trình máy tính, và “học” miêu tả cách mà các thuật toán học máy trở nên chính xác hơn sau một quá trình tiếp nhận dữ liệu bổ sung.
Machine learning cho phép máy tính giải quyết các tác vụ mà trước đây chỉ con người mới thực hiện được – từ phiên dịch cho đến lái xe, học máy đã và đang tạo tiền đề cho sự bùng nổ của trí tuệ nhân tạo, giúp phần mềm nhận thức được thế giới thực vốn rất phức tạp và không thể dự đoán được.
Khái niệm học máy không hề mới mẻ, nhưng nó chỉ thực sự được ứng dụng trong doanh nghiệp khi internet trở nên phổ biến cùng những thành tựu gần đây trong lĩnh vực phân tích dữ liệu lớn và điện toán đám mây. Nguyên nhân là bởi việc huấn luyện thuật toán học máy tìm kiếm mẫu hình trong dữ liệu đòi hỏi rất nhiều tài nguyên điện toán và phải tiếp cận được dữ liệu lớn.
Machine learning thường được chia thành 4 nhóm chính: học giám sát, học không giám sát, học nửa giám sát, và học tăng cường.
Về cơ bản, đây là phương pháp dạy máy thông qua ví dụ.
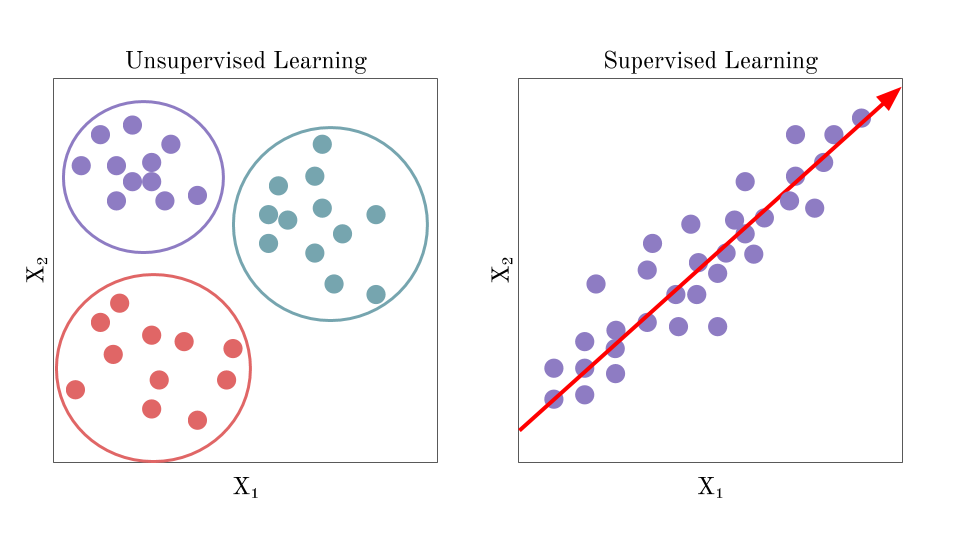
Trong quá trình học giám sát, các hệ thống sẽ được truyền đạt những lượng lớn dữ liệu có gắn nhãn, ví dụ như hình ảnh những con số viết tay được ghi chú để chỉ rõ chúng tương ứng với con số nào. Khi được truyền đạt đủ ví dụ, một hệ thống học giám sát sẽ học được cách nhận biết những cụm điểm ảnh và hình dáng gắn liền với mỗi con số, và cuối cùng sẽ có thể nhận biết được những con số viết tay, phân biệt được chính xác những con số như 9 và 4, hay 6 và 8.
Tuy nhiên, huấn luyện những hệ thống như vậy đòi hỏi lượng dữ liệu gắn nhãn rất lớn – một số hệ thống cần đến hàng triệu ví dụ mới thuần thục một tác vụ nhất định!
Kết quả là, bộ dữ liệu được sử dụng để huấn luyện các hệ thống đó có thể cực “khủng” (bộ dữ liệu Open Images của Google có đến khoảng 9 triệu ảnh, kho video gắn nhãn YouTube-8M có 7 triệu video gắn nhãn, và ImageNet, một trong những cơ sở dữ liệu đầu tiên thuộc loại này, có hơn 14 triệu ảnh được sắp xếp theo từng danh mục).
Quy trình gắn nhãn cho các bộ dữ liệu dùng trong học giám sát thường được thực hiện thông qua các dịch vụ tuyển dụng tự do, như Amazon Mechanical Turk. Ví dụ, ImageNet được xây dựng trong hơn 2 năm bởi gần 50.000 người, chủ yếu được tuyển dụng thông qua Amazon Mechanical Turk.
Ngược lại, học không giám sát sẽ giao nhiệm vụ cho các thuật toán xác định mẫu hình trong dữ liệu, có gắng phát hiện những điểm tương đồng dùng để chia dữ liệu vào các danh mục.
Ví dụ như Airbnb gom nhóm các nhà còn chỗ cho thuê theo từng khu phố, hoặc Google News gộp các tin tức về chủ đề tương tự mỗi ngày.
Các thuật toán học không giám sát không được thiết kế để lọc ra những loại dữ liệu cụ thể – chúng đơn giản là tìm kiếm dữ liệu có thể được gom nhóm thông qua những điểm tương đồng, hoặc tìm những điểm bất thường trong dữ liệu.
Kỹ thuật này dựa vào một lượng nhỏ dữ liệu gắn nhãn và một lượng lớn dữ liệu chưa gắn nhãn để huấn luyện hệ thống. Dữ liệu gắn nhãn được sử dụng để huấn luyện cơ bản một mô hình học máy, sau đó mô hình đã qua huấn luyện cơ bản này sẽ được sử dụng để gắn nhãn dữ liệu chưa gắn nhãn – một quy trình gọi là “gắn nhãn giả”. Mô hình sau đó sẽ được huấn luyện bằng tổng hợp dữ liệu gắn nhãn và gắn nhãn giả.
Hiệu suất học nửa giám sát thời gian qua đã được cải thiện khá nhiều nhờ các Mạng đối nghịch tạo sinh (GAN), tức các hệ thống học máy có thể sử dụng dữ liệu gắn nhãn để tạo ra dữ liệu hoàn toàn mới, từ đó lại sử dụng dữ liệu mới để giúp huấn luyện một mô hình học máy.
Học tăng cường giống như bạn lần đầu học chơi một tựa game máy tính vậy – lúc này bạn chưa quen với luật chơi hoặc cách điều khiển trong game. Dù bạn hoàn toàn “gà mờ”, nhưng dần dần khi quan sát mối liên hệ giữa các nút bấm, điều xảy ra trên màn hình và điểm số trong game, thì kết quả bạn thu được sẽ dần tốt hơn.
Một ví dụ về học tăng cường là mạng Deep Q của Google DeepMind, vốn nổi tiếng vì đánh bại con người trong nhiều tựa game máy tính cổ điển. Hệ thống này được cho xem các điểm ảnh từ mỗi game và xác định các thông tin về trạng thái của game, như khoảng cách giữa các vật thể trên màn hình. Sau đó nó sẽ đánh giá trạng thái của game và các hành động nó thực hiện trong game trong mối tương quan với điểm số đạt được.
Qua nhiều vòng chơi, hệ thống đã xây dựng được một mô hình trong đó các hành động đưa ra sẽ mang về điểm số tối đa – ví dụ trong game Breakout, hệ thống biết nên di chuyển bệ đỡ ra sao để bắt được trái banh.
Các hệ thống học máy được sử dụng ở khắp nơi, và ngày nay đã trở thành một trụ cột của internet hiện đại. Chúng là thứ đưa ra khuyến nghị về sản phẩm bạn có thể muốn mua trên Amazon, hay video bạn có thể muốn xem trên Netflix.
Mọi truy vấn tìm kiếm Google đều cần đến học máy, để hiểu được ngôn ngữ người dùng nhập vào rồi từ đó cá nhân hoá kết quả tìm kiếm. Tương tự, bộ lọc spam và phishing của Gmail sử dụng các mô hình học máy để giữa cho hộp thư của bạn luôn an toàn.
Một trong những sản phẩm đặc trưng thể hiện sức mạnh của học máy là các trợ lý ảo, như Siri, Alexa, Google Assistant, và Cortana. Chúng đều dựa vào học máy để hỗ trợ các tính năng nhận diện giọng nói và hiểu ngôn ngữ tự nhiên, cũng như “càn quét” các kho tàng trực tuyến để trả lời các truy vấn.

Nhưng đó chỉ là bề nổi. Trên thực tế, các hệ thống học máy được ứng dụng trong gần như mọi ngành công nghiệp, bao gồm:
Năm 2020, GPT-3 của OpenAI đã khiến cả thế giới choáng ngợp vì khả năng viết lách như con người, về gần như bất kỳ chủ đề nào bạn có thể nghĩ đến.
GPT-3 là mạng lưới thần kinh được huấn luyện dựa trên hàng tỷ bài viết tiếng Anh trên web và có thể tạo ra các bài viết cũng như đưa ra câu trả lời cho mọi truy vấn.
Và sẽ đến một ngày, học máy sẽ mở đường cho những con robot với khả năng học trực tiếp từ con người – hiện các nhà nghiên cứu từ Nvidia đang chế tạo một hệ thống học sâu được thiết kế để dạy robot cách thực hiện một tác vụ mà chỉ cần quan sát con người thực hiện công việc đó!
AIVA – Trợ lý ảo toàn năng
Các tìm kiếm liên quan đến chủ đề “Machine learning là gì”
| giáo trình học máy (machine learning) | Machine Learning cơ bản | Machine Learning Engineer là gì | Học Machine Learning bắt đầu từ đầu |
| Machine learning | Học máy la gì | Machine là gì | Machine learning workflow |
Midjourney AI là gì? Hướng dẫn 5 bước chi tiết để tạo ảnh bằng AI
Poe AI là gì? Tại sao bạn nên sử dụng ngay trợ thủ AI siêu tiện lợi này?
6 công cụ thiết kế logo bằng trí tuệ nhân tạo tốt nhất năm 2023



