- VIE
- VIE
- ENG
Crawl Web là một công cụ hỗ trợ đắc lực cho các marketer hiện nay. Công cụ này đề cập đến quá trình tự động thu thập thông tin từ các trang web trên Internet. Vậy Crawl Web hoạt động như thế nào? Vai trò của Crawl là gì? Hãy cùng TenTen đi tìm hiểu ngay sau đây.
Crawl Web là quá trình tự động thu thập thông tin từ các trang web trên internet bằng cách sử dụng các chương trình máy tính được gọi là web crawler (hay spider, robot hoặc bot). Quá trình này được thực hiện bằng cách gửi yêu cầu HTTP đến các trang web và sau đó phân tích các phản hồi để lấy các tài nguyên như văn bản, hình ảnh, video, âm thanh, tệp tin, vv.
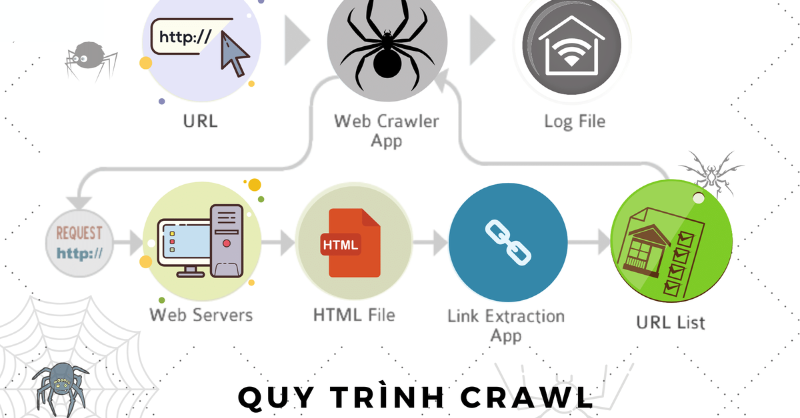
Các web crawler sẽ bắt đầu từ một trang web cụ thể và theo dõi các liên kết trên trang đó để truy cập vào các trang khác. Các trang web khác sẽ được quét và lặp lại quá trình này cho đến khi tất cả các trang liên quan được thu thập.
Khi một trang web được thu thập, các thông tin được lấy sẽ được lưu trữ trong một cơ sở dữ liệu để sau đó được sử dụng bởi các công cụ tìm kiếm hoặc các ứng dụng khác.
Crawl Web là một công cụ quan trọng cho việc thu thập dữ liệu trên internet và được sử dụng để nghiên cứu thị trường, phân tích dữ liệu, đánh giá hiệu quả của các chiến dịch tiếp thị kỹ thuật số, vv.
Tuy nhiên, việc sử dụng web crawler cũng có thể gây ra một số vấn đề liên quan đến quyền riêng tư và bản quyền, do đó việc sử dụng chúng cần tuân thủ các quy định pháp lý và đạo đức.
Nhưng ở phần “Định nghĩa Crawl là gì?” ta có thể thấy Crawl là một công cụ quan trọng trong việc tìm kiếm thông tin trên mạng. Internet là một kho tàng thông tin lớn, với hàng tỷ trang web và triệu trăm nghìn trang web được tạo ra hàng ngày.
Việc tìm kiếm thông tin trên internet là một thách thức lớn và đòi hỏi nhiều thời gian và công sức. Đây là lý do tại sao Crawl Web trở thành một công cụ quan trọng.
Crawl Web cho phép thu thập thông tin từ hàng triệu trang web trên internet, giúp tìm kiếm thông tin rộng rãi và đa dạng hơn. Nó cung cấp cho người dùng nhiều lựa chọn để tìm kiếm thông tin, từ các trang web phổ biến đến các trang web chuyên ngành, từ các trang web về giải trí đến các trang web về khoa học và công nghệ.
Các chương trình Crawl Web có khả năng thu thập thông tin từ hàng ngàn trang web trong thời gian ngắn, mang lại sự tiện lợi và nhanh chóng cho người dùng.
Việc sử dụng Crawl Web giúp cập nhật thông tin thường xuyên và đảm bảo rằng thông tin được tìm kiếm là mới nhất. Do số lượng trang web trên internet luôn tăng lên, Crawl Web là công cụ cần thiết để cập nhật thông tin thường xuyên.
Bằng cách sử dụng Crawl Web, người dùng có thể đảm bảo rằng thông tin tìm kiếm của họ là chính xác và được cập nhật.
Các công cụ tìm kiếm sử dụng dữ liệu được thu thập từ Crawl Web để tối ưu hoá kết quả tìm kiếm. Bằng cách sử dụng các thuật toán phân tích dữ liệu, các công cụ tìm kiếm có thể cung cấp cho người dùng những kết quả tìm kiếm chính xác và liên quan nhất.
Crawl Web cũng cung cấp dữ liệu phong phú cho các nhà nghiên cứu, những người quan tâm đến phân tích dữ liệu và đánh giá hiệu quả của các chiến dịch tiếp thị kỹ thuật số.
Tóm lại, Crawl Web là một công cụ quan trọng giúp tìm kiếm thông tin trên mạng và cung cấp nhiều lợi ích cho người dùng, từ việc thu thập thông tin rộng rãi, cập nhật thông tin thường xuyên, đến phân tích dữ liệu và tối ưu hoá kết quả tìm kiếm.
Việc sử dụng Crawl Web giúp người dùng tiết kiệm thời gian và công sức trong việc tìm kiếm thông tin trên internet và giúp họ đạt được kết quả tìm kiếm chính xác và liên quan nhất.
Quá trình tìm kiếm và lựa chọn trang web để tải về trong Crawl Web bao gồm các bước từ tìm kiếm trang web, xác định độ ưu tiên của trang web, đánh giá độ sâu của trang web, lựa chọn trang web để tải về, tải về và lưu trữ thông tin, và cuối cùng là duy trì và cập nhật dữ liệu thu thập được.
Phân tích cấu trúc của trang web trong Crawl Web bao gồm các bước từ phân tích cấu trúc HTML, phân tích cấu trúc CSS và JavaScript, xác định sự liên kết giữa các trang web, xác định độ sâu của trang web, đánh giá độ ưu tiên của các phần tử trên trang web.
Quá trình này giúp các web crawler hiểu được cấu trúc của trang web và thu thập thông tin một cách hiệu quả.
Lưu trữ và phân tích dữ liệu thu thập được trong Crawl Web là quá trình quan trọng để có thể sử dụng thông tin đó một cách hiệu quả.
Quá trình này bao gồm các bước sau:
Sau khi hiểu được Crawl là gì, ta sẽ tìm kiếm công cụ Crawl Web phổ biến, có thể kể đến như Googlebot của Google, Bingbot của Bing, Yandexbot của Yandex.
Googlebot là một phần mềm robot được phát triển bởi Google để thu thập thông tin từ các trang web và cập nhật cơ sở dữ liệu của Google. Việc sử dụng Googlebot có thể giúp cho các nhà phát triển web hoặc các chuyên gia SEO bao gồm:
Đảm bảo rằng trang web của bạn được tìm thấy trên Google: Khi Googlebot thu thập thông tin từ trang web của bạn, nó sẽ đưa thông tin đó vào cơ sở dữ liệu của Google và đưa trang web của bạn lên các trang kết quả tìm kiếm của Google.
Vì vậy, sử dụng Googlebot có thể giúp đảm bảo rằng trang web của bạn được tìm thấy trên Google và được hiển thị cho người dùng.

Kiểm tra sự tương thích của trang web với các tiêu chuẩn SEO: Googlebot sẽ thu thập các thông tin liên quan đến trang web của bạn, bao gồm tiêu đề, nội dung, liên kết và các yếu tố khác.
Các chuyên gia SEO có thể sử dụng các thông tin này để kiểm tra sự tương thích của trang web với các tiêu chuẩn SEO và đưa ra các cải tiến để tối ưu hóa trang web của họ.
Xác định thứ hạng của trang web trên kết quả tìm kiếm của Google: Googlebot được sử dụng để xác định thứ hạng của các trang web trên kết quả tìm kiếm của Google. Các chuyên gia SEO có thể sử dụng các thông tin này để đưa ra các chiến lược tối ưu hóa nội dung để cải thiện thứ hạng của trang web của họ.
Theo dõi các thay đổi trên trang web: Googlebot cập nhật cơ sở dữ liệu của Google khi có sự thay đổi trên trang web. Vì vậy, sử dụng Googlebot có thể giúp cho các chuyên gia SEO theo dõi các thay đổi trên trang web của họ và đưa ra các điều chỉnh cần thiết để tối ưu hóa trang web của họ.
Có thể bạn quan tâm: 5 lựa chọn plugin WordPress quiz tốt nhất 2023 bạn cần biết
Bingbot là một phần quan trọng của hệ thống tìm kiếm của Bing và được sử dụng để cung cấp các kết quả tìm kiếm chính xác và đáng tin cậy cho người dùng. Các công việc chính của Bingbot bao gồm:
Yandexbot là một phần quan trọng của hệ thống tìm kiếm của Yandex và được sử dụng để cung cấp các kết quả tìm kiếm chính xác và đáng tin cậy cho người dùng. Các công việc chính của Yandexbot bao gồm:
Sau đó, Yandexbot sẽ lưu trữ các thông tin này vào cơ sở dữ liệu của Yandex để sử dụng cho các trang kết quả tìm kiếm.

Yandexbot cũng sẽ theo dõi các thay đổi trên trang web và cập nhật cơ sở dữ liệu của Yandex khi có sự thay đổi.
Yandexbot đánh giá các yếu tố như nội dung trang web, độ tin cậy, sự tương thích với các tiêu chuẩn SEO, vv. để xác định thứ hạng của trang web trên kết quả tìm kiếm của Yandex.
Vừa rồi TenTenvn đã mang đến bạn đọc những thông tin thú vị về “Crawl là gì? Khái niệm và cách hoạt động Crawl Web” . Nhìn chung, Crawl là một quá trình quan trọng trong SEO và tìm kiếm trên Internet.
Crawl web giúp các công cụ tìm kiếm thu thập thông tin từ các trang web và cung cấp kết quả tìm kiếm chính xác và đáng tin cậy cho người dùng.
Crawl Web cũng giúp nâng cao thứ hạng của trang web trên kết quả tìm kiếm, ngăn chặn các trang web spam và giúp người quản trị website hiểu rõ hơn về cách các công cụ tìm kiếm hoạt động.
|
Crawl data la gì
|
Crawl đọc tiếng anh là gì | Crawler nghĩa là gì | Crawl web la gì |
| Crawl into là gì | Crawl out là gì | The crawl | Crawled là gì |
Bài liên quan