- VIE
- VIE
- ENG
Stable Audio là cái tên được nhắc đến khá nhiều trong thời gian qua, đặc biệt với những ai thường xuyên nghiên cứu về AI tạo sinh. Vậy Stable Audio là gì? Hãy cùng Tenten.vn tìm hiểu nhé!
Tăng 300% hiệu suất công việc với AI
Bạn sẽ học được gì?
|
 |

Stability AI là một công ty khởi nghiệp công nghệ cao được thành lập vào năm 2022 bởi một nhóm các nhà nghiên cứu và kỹ sư từ Đại học California, Berkeley. Công ty tập trung vào việc phát triển các thuật toán AI ổn định và có thể mở rộng, với mục tiêu giải quyết một số thách thức lớn nhất trong lĩnh vực AI hiện nay.
Sản phẩm chính của Stability AI là Stable Diffusion, một kiến trúc mạng thần kinh mới cho phép tạo ra các hình ảnh chất lượng cao với độ nhiễu thấp. Stable Diffusion đã được chứng minh là vượt trội hơn các mô hình diffusion khác về độ chính xác và ổn định.
Ngoài Stable Diffusion, Stability AI cũng đang phát triển các công nghệ AI ổn định khác, bao gồm:
– Stable GAN: Một kiến trúc mạng đối lập cho phép tạo ra các hình ảnh và video chân thực hơn.
– Stable RL: Một thuật toán học máy mạnh mẽ có thể được sử dụng để giải quyết các vấn đề phức tạp với độ nhiễu thấp.
– Stable MLOps: Một bộ công cụ giúp nhà phát triển triển khai và vận hành các mô hình AI ổn định.
Stability AI được hỗ trợ bởi một số quỹ đầu tư mạo hiểm hàng đầu, bao gồm Sequoia Capital, Andreessen Horowitz, và Y Combinator. Công ty hiện có trụ sở tại San Francisco, California.

Stable Audio là sản phẩm mới nhất của Stability AI. Đây là một mô hình khuếch tán tiềm ẩn được thiết kế để cách mạng hóa lĩnh vực tạo sinh âm thanh.
Stable Audio sử dụng mô hình khuếch tán tương tự như Stable Diffusion, nhưng trong trường hợp này nó được huấn luyện với âm thanh thay vì hình ảnh. Người dùng có thể sử dụng nó để tạo ra các bài hát hoặc nhạc nền cho bất kỳ dự án nào.
Các mô hình khuếch tán âm thanh thường có xu hướng tạo ra một đoạn âm thanh với độ dài cố định, rất không phù hợp cho việc sản xuất nhạc bởi các bài hát có thể có độ dài khác nhau. Nền tảng mới của Stability AI cho phép người dùng tạo âm thanh với độ dài tùy ý, tức là công ty đã phải huấn luyện nó bằng âm nhạc và thêm siêu dữ liệu văn bản vào các vị trí đầu và cuối bài hát.
Trước đây, khi bạn dạy AI một đoạn âm thanh dài 30 giây, nó sẽ chỉ tạo ra được một đoạn âm thanh khác dài 30 giây và sau đó là những đoạn bằng nhau của một bài hát. Stability AI cho biết mô hình hiện nay đã cho phép người dùng Stable Audio nắm quyền kiểm soát sâu hơn đối với độ dài bài hát.
Theo công ty, họ đã huấn luyện Stable Audio với “một bộ dữ liệu chứa hơn 800.000 tập tin âm thanh có chứa nhạc, hiệu ứng âm thanh, và các đoạn nhạc sử dụng nhạc cụ đơn, kết hợp với siêu dữ liệu văn bản từ công ty bản quyền âm nhạc AudioSparx. Bộ dữ liệu này có tổng thời lượng âm thanh lên đến hơn 19.500 giờ! Do hợp tác với một công ty bản quyền âm nhạc, nên Stability AI khẳng định có giấy phép sử dụng bất kỳ tư liệu âm thanh nào đã được đăng ký bản quyền.
Một trong những tính năng nổi bật của Stable Audio là việc nó sử dụng kỹ thuật downsampled latent representation (tạo ra một biểu diễn ẩn của dữ liệu gốc, trong đó dữ liệu đã được giảm kích thước hoặc mẫu, nhằm giảm bộ nhớ và tối ưu hóa tính toán khi làm việc với dữ liệu lớn hoặc khi cần truyền tải dữ liệu qua mạng với băng thông hạn chế) đối với âm thanh, nhờ đó tăng tốc đáng kể thời gian suy luận so với âm thanh thuần.
Thông qua kỹ thuật khuếch tán mẫu tiên tiến, mô hình Stable Audio có thể tạo ra 95 giây âm thanh stereo ở sample rate 44.1 kHz trong chưa đầy 1 giây khi kết hợp với GPU NVIDIA A100.
Ở thời điểm hiện tại thì chưa. Tính đến tháng 9/2023, Stability AI vẫn chưa tung ra mô hình hay mã nguồn để huấn luyện một mô hình tương tự Stable Audio.
Tuy nhiên, Harmonai, một phòng thí nghiệm nghiên cứu dưới trướng Stability AI, hứa hẹn sẽ tung ra một mô hình mã nguồn mở dựa trên kiến trúc Stable Audio nhưng dựa trên một bộ dữ liệu huấn luyện khác, cùng với mã nguồn huấn luyện để người dùng có thể tạo ra các mô hình tạo sinh nhạc theo ý muốn.
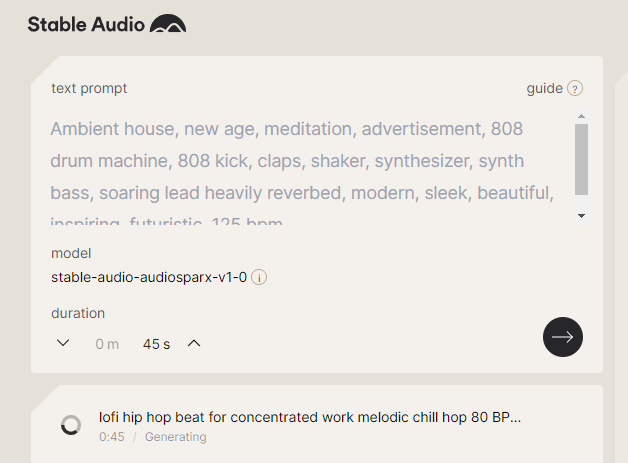
Stable Audio sẽ có 3 mức giá:
– Phiên bản miễn phí cho phép người dùng tạo đoạn âm thanh tối đa 45 giây, giới hạn 20 đoạn mỗi tháng. Người dùng sẽ không được sử dụng âm thanh đã tạo cho mục đích thương mại.
– Phiên bản Professional giá 11,99 USD cho phép tạo đoạn âm thanh tối đa 90 giây, giới hạn 500 đoạn mỗi tháng.
– Phiên bản Enterprise, trong đó các công ty có thể tùy biến hạn mức sử dụng và giá tùy theo nhu cầu.
Nhìn chung, các hệ thống có khả năng chuyển đổi văn bản sang âm thanh không phải là điều mới mẻ, khi mà đã có khá nhiều tên tuổi lớn trong lĩnh vực AI tạo sinh nghiên cứu về ý tưởng này.
Meta từng tung ra AudioCraft – một tập hợp các mô hình AI tạo sinh hỗ trợ người dùng tạo ERM, âm thanh, và nhạc tự nhiên từ câu lệnh văn bản – hồi tháng 8 vừa qua. AI này hiện chỉ được phổ biến đến các nhà nghiên cứu và một số chuyên gia về âm thanh.
MusicLM của Google cũng là một AI khác cho phép người dùng tạo âm thanh, nhưng hiện chỉ dành cho các nhà nghiên cứu.
Giống như các nền tảng AI tạo sinh âm thanh khác, tiềm năng của Stable Audio nằm ở khả năng tạo nhạc nền cho podcast hoặc video, nhằm giúp đẩy nhanh tốc độ luồng công việc liên quan.
Tăng 300% hiệu suất công việc với AI
Bạn sẽ học được gì?
|
|
Top 5 công cụ AI tự động và tối ưu hóa chiến lược Marketing bạn cần biết
[HOT] Chính thức ra mắt MiraBOT – Master your Data – Chatbot AI đầu tiên tại Việt Nam
Cách sử dụng Google Bard tìm thông tin trên Gmail và Docs bạn cần biết
Mọi thứ bạn cần biết về DALL-E 3, chuẩn mực mới của AI tạo sinh hình ảnh



